Analyzing GPT-4 Tokens
May 2, 2024
4 min read
I recently watched a YouTube video by Andrej Karpathy explaining the quirky behavior of LLMs through their tokenizers. He addresses questions such as why LLMs struggle with spelling or react unpredictably to specific terms like SolidGoldMagikKarp. If you haven't seen this video yet, I highly recommend it.
Karpathy explains that tokens are akin to the atoms of large language models, shaping how they perceive and interact with text. This inherent structure not only facilitates but also limits their capabilities. He notes that the tokens for OpenAI models, like GPT-4, are publicly accessible. This caught my attention and I decided to examine these tokens using Llama3, a capable and freely available large language model that I could run on my own laptop.
Method
The tokens for GPT-4 are accessible through a link found in OpenAI's GitHub repository for the TikToken. These tokens are encoded in Base64, requiring decoding to reveal a list of approximately 100,000 tokens. The initial entries mostly consist of single or dual characters. As the list progresses, it begins to include full words and fragments of words.
available
mt
Bl
...
block
Input
keep
Count
open
['
throw
uilder
Action
things
True
url
Bo
This list includes fragments that resemble syntax elements or identifiers from various programming languages. My goal was to categorize all the tokens using Llama3 into the following categories:
- Natural languages
- English (en)
- Spanish (es)
- German (de)
- etc.
- Computer languages
- Java
- C#
- Python
- etc.
Prompting
After some trial and error, I created the following prompt for Llama3:
You are a token categorizer. You categorize lists of tokens into types: code, lang, unknown. The types have the following definitions:
- code: tokens that are part of a programming language (such as Python, JavaScript abbreviated as "js", C#, etc.)
- lang: tokens that are part of some natural language.
- unknown: are single characters or tokens where the origin cannot be assessed.
The next categorization is lang. This specifies which language this is part of. The corresponding languages are:
- for type code: "javascript", "c#", "python", "java", "unknown", etc.
- for type lang: "en", "es", "de", "nl", "unknown", etc.
- for type unknown: leave this empty.
Also, add a property called definition to the objects. It should contain a short description of the token. It should not be longer than a few words. The results should be presented in a JSON structure that clearly defines categories for each token. Here’s an example of how to structure this JSON:
Input:
liability beam NotFound Charles .SequentialGroup олько _person .history TextView __ ís Markt onDataChange photoshop
Output:
{
"liability": {"type": "lang", "lang": "en", "definition": "Legal responsibility"},
"beam": {"type": "lang", "lang": "en", "definition": "Line of light"},
"NotFound": {"type": "code", "lang": "javascript", "definition": "Error message"},
"Charles": {"type": "lang", "lang": "en", "definition": "Name"},
".SequentialGroup": {"type": "code", "lang": "java", "definition": "Linear processing"},
"олько": {"type": "lang", "lang": "ru", "definition": "Only"},
"_person": {"type": "code", "lang": "python", "definition": "Individual"},
".history": {"type": "code", "lang": "javascript", "definition": "Past events"},
"TextView": {"type": "code", "lang": "java", "definition": "Text display"},
"__": {"type": "unknown", "lang": "", "definition": ""},
"ís": {"type": "unknown", "lang": "", "definition": ""},
"Markt": {"type": "lang", "lang": "de", "definition": "Market or fair"},
"onDataChange": {"type": "code", "lang": "unknown", "definition": "Data update"},
"photoshop": {"type": "lang", "lang": "en", "definition": "Image editing software"}
}
Do a linguistic analysis of each token. Respond only with valid JSON. Do not add backticks.
I stored the JSON result of this prompt in a SQLite database to facilitate easier analysis of the different categories. I used a Python script and the Ollama endpoints for this.
Results
After a few nights of hard work, Llama3 had processed about 97% of the tokens, and the results are illuminating.
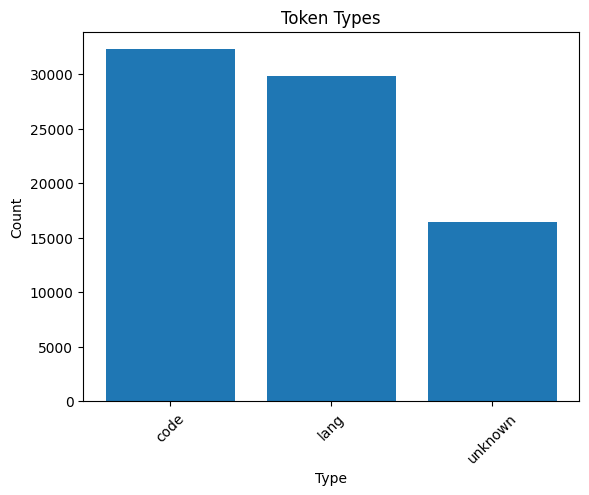
As you can see, the majority of GPT-4's tokens are related to coding. The unknown category includes single characters or groups of characters that could not be clearly categorized.
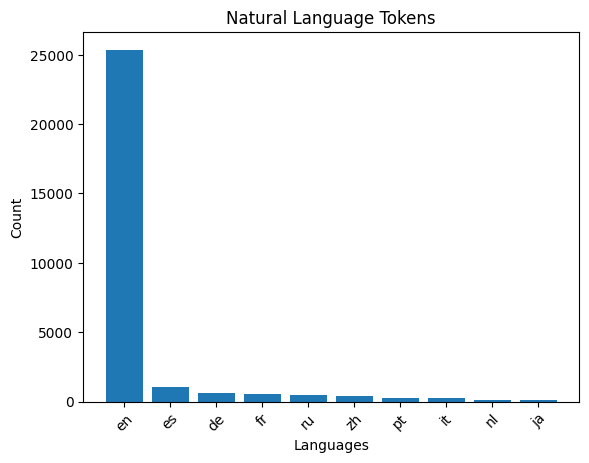
Focusing on natural language tokens, a significant majority are identified as English words or fragments. Spanish, the second most represented language, has only 1064 tokens.
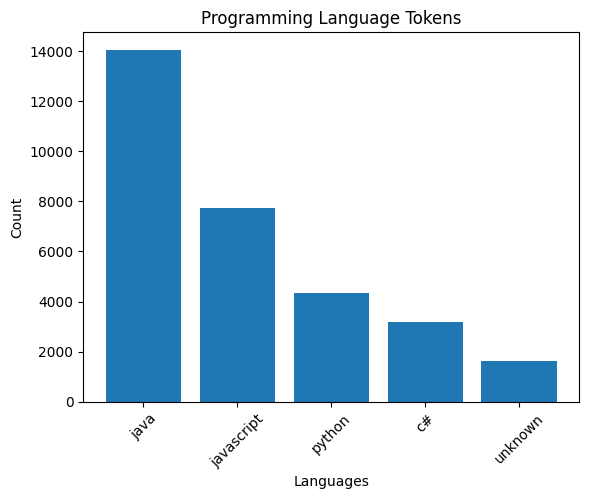
The analysis of programming languages shows Java and JavaScript leading. However, categorizing syntax elements is complex. For example, the token getFullYear is classified under Java but could also belong to JavaScript. So I would not read too much into this chart.
Conclusions
The reliability of Llama3's categorization is questionable, not due to its limitations but because of the inherent challenge in accurately categorizing small word or code fragments. Nevertheless, this analysis provides intriguing insights into the possible biases in GPT-4.
It is evident that GPT-4 has a stronger focus on English than I anticipated. Of course the main language of the internet is English, but I only counted 124 tokens that could be classified as Dutch words. This could partially explain why GPT-4 underperforms in my native language
Surprisingly, the tokens are more code-centric than I expected. While I assumed a greater emphasis on natural language tokens across various languages, the data suggests a reliance on code, at least in training the tokenizer.
I hope you found this post interesting. This was my first attempt at using a large language model for a categorization task. The implementation scripts are straightforward, but I had to invest more in error handling and recovery so that the analysis would keep running even when a prompt failed to deliver a parsable result.